
IBM Data Course 9: Applied DS Capstone
Posted on 17/05/2019, in Data Science, Python, Machine Learning.This note was first taken when I learnt the IBM Data Professional Certificate course on Coursera.
settings_backup_restore
Go back to Course 8 (week 4 to 6).
tocIn this post
Week 1 : Introduction to Capstone Project
- You live on the west side of the city of Toronto in Canada. You love your neighborhood
- Now say you receive a job offer from a great company on the other side.
- However given the far distance from your current place
- You must move if you decide to accept the offer.
- The neighborhoods on the other side of the city that are exactly the same as your current neighborhood? and if not perhaps similar neighborhoods that are at least closer to your new job?
- Name : Battle of the neighborhoods
- Jobs:
- Segment a city into different neighborhoods using the geographical coordinates of the center of each neighborhood.
- Using a combination of location data and machine learning, you will group the neighbourhoods into clusters
- 5 modules
- Module 1 to 3: learn additional skills.
- Module 4 & 5: the project.
Location Data Providers
- Location data is data describing places and venues, such as their geographical location, their category, working hours, full address, and so on, such that for a given location given in the form of its geographical coordinates (or latitude and longitude values) one is able to determine what types of venues exist within a defined radius from that location.
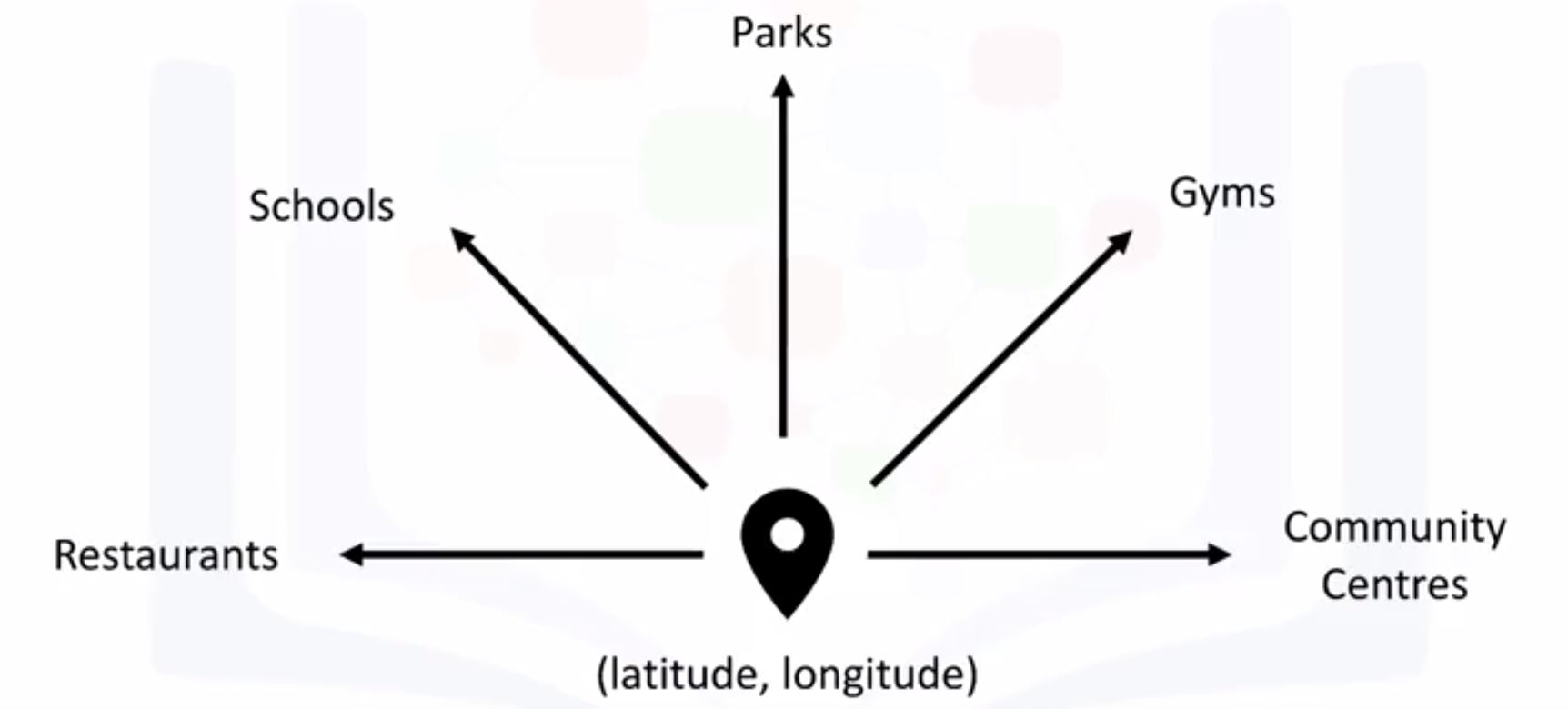
- Location data provider: Foursquare, Google places, Yelp
- Rate limit: How many API calls you can make (per hour, per day)
- Cost: How much does it cost?
- Coverage: how many countries or geographical locations the location data set covers.
- Accuracy: how accurate is the location data provided
- Update frequecy: How often the data are updated?
- In this project, we use Foursquare.
- My assignment: create a repository with a jupyter notebook on Github.
Week 2 : Foursquare API
Introduction to Foursquare
- accurate location data.
- Apple maps, uber, snapchat, twitter,…
- Create an account on FS.
Using Foursquare API
What we can do?
- Search for a specific type of venue around a given location - Regular
- Learn more about a specific venue - Premium.
- Learn more about a specific Foursquare user - Regular
- Explore a given location - Regular
- Explore trending venues around a given location - Regular


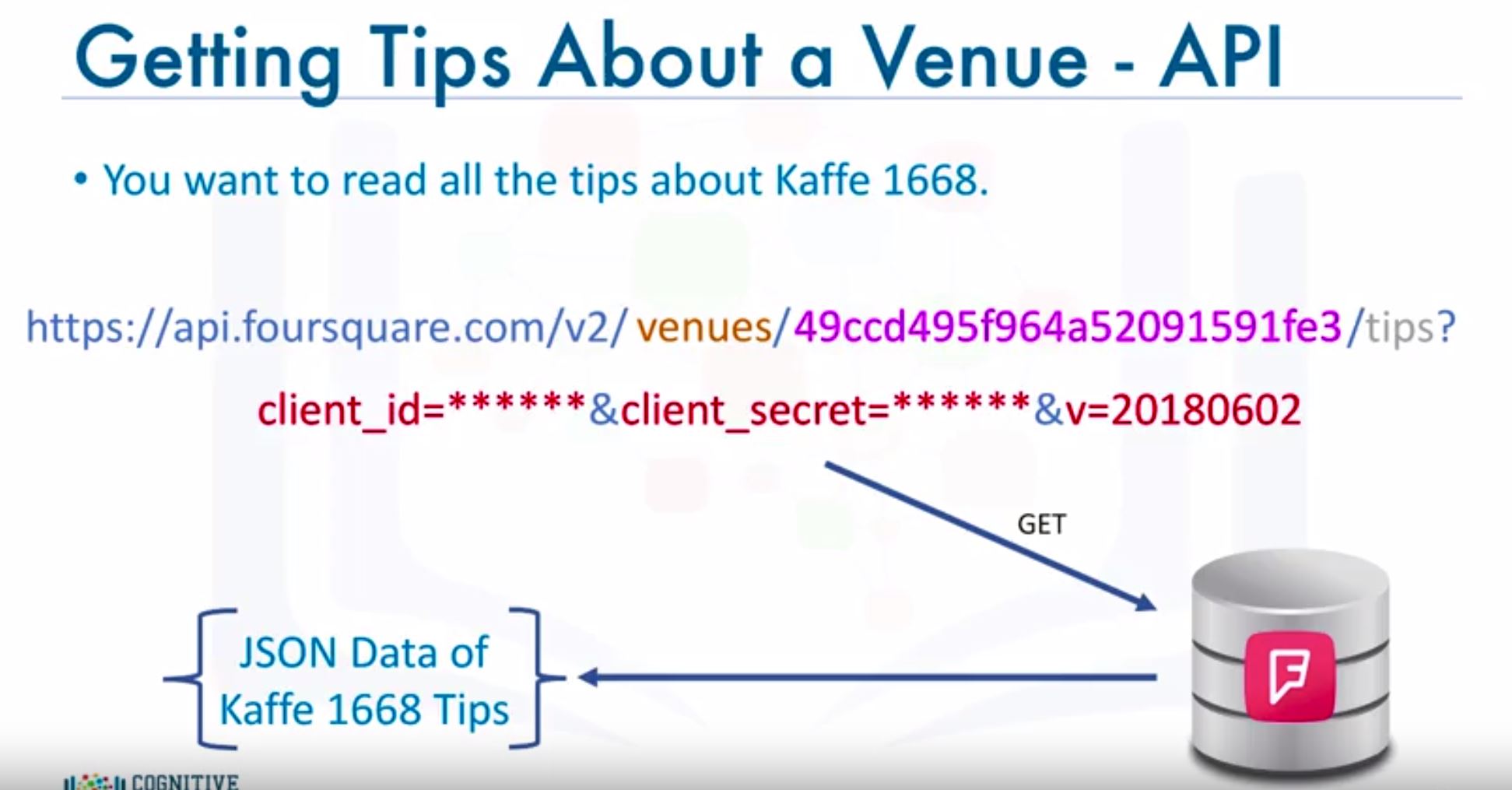
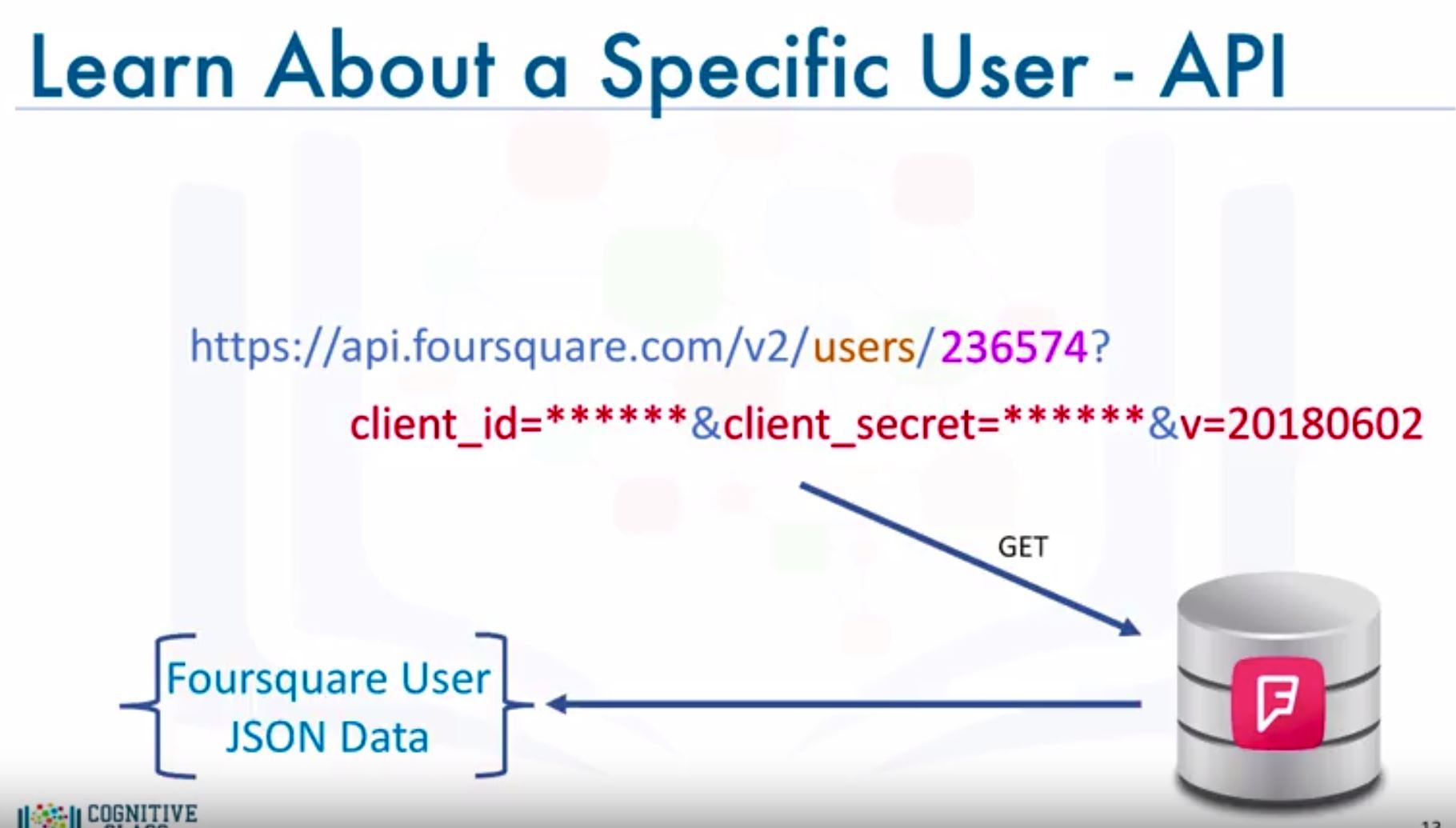
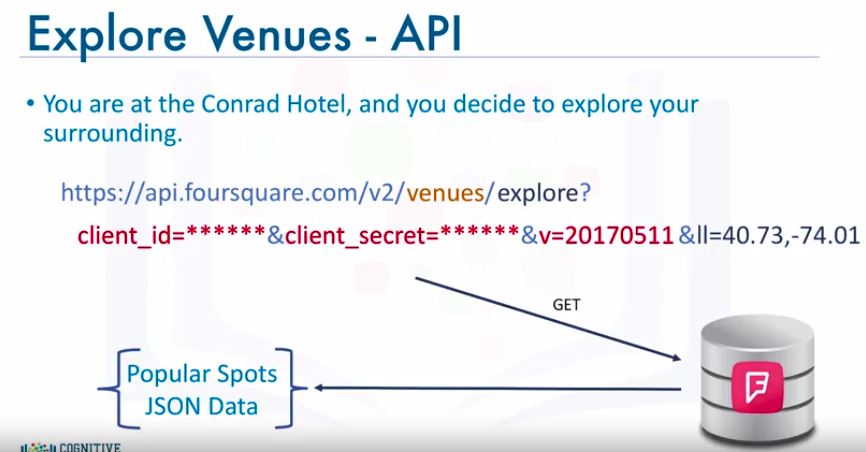

LAB : Foursquare API
Learning FourSquare API with Python
Week 3 : Neighborhood Segmentation and Clustering
- You’ll learn AGAIN clustering & K-means (look this note of course 8)
- Another lab for K-means clustering beside this old lab.
- Lab : Segmenting and Clustering Neighborhoods in New York City
Assignment : Segmenting and Clustering Neighborhoods in Toronto
My solution for this assignment
- unlike New York, the neighborhood data is not readily available on the internet
- a Wikipedia page exists that has all the information we need to explore and cluster the neighborhoods in Toronto. You will be required to scrape the Wikipedia page and wrangle the data, clean it, and then read it into a pandas dataframe so that it is in a structured format like the New York dataset.
- Use this tool and this tutorial to scrap.
- Or use this tutorial to scrap a table in a wiki page.
- How to couple BeautifulSoup with pandas dataframe, check this.
Install beatifulsoup4
pip install beautifulsoup4
# It should return something like "Requirement already satisfied: beautifulsoup4 in c:\programdata\anaconda3\lib\site-packages (4.6.0)"
# sometimes you need to upgrade your pip
python -m pip install --upgrade pip --user
Install other required libs
pip install lxml
pip install html5lib
pip install requests
Scrape html from source
Follow this instruction of Corey. Install all required packages like previous section and then do these,
from bs4 import BeautifulSoup
import requests
source = requests.get('<url>').text
soup = BeautifulSoup(source, 'lxml') // all html content of <url>
print(soup.prettify()) # print with indents
match = soup.div # get the first div
soup.h2 # first h2
soup.find('div') # find first div found
soup.find('div', class_='footer') # find first div whose class is "footer"
# find all div with class "article"
for article in soup.find_all('div', class_="article"):
headline = article.h2.a.text # a tag
summery = article.p.text # p tag
# access src in an iframe
# <iframe class=""youtube-player ... src="" ....></iframe>
vid_src = article.find("iframe", class_="youtube-player")["src"]
Week 4 & 5 : The Battle of Neighborhoods
My solution for this assignment & a blog about it.
Examples of already-done works: